Tim Groeneveld
Random musings from the world of an Open Source geek
Converting a list of GPS locations (lat, long) to Australian state names
/ | Leave a CommentRecently, I had the fun experience of converting a CSV file that contained the names of a bunch of cities inside Australia. The CSV file contained four columns:
- City name
- Latitude (in DMS)
- Longitude (in DMS)
There were more than 5,000 rows in the CSV file. I wanted to pull a list of all the cities, and determine what state they were in.
Instead of using the Google Maps API (and getting charged ~$35), I decided to hunt down a way that I could use open data provided by the Australian Bureau of Statistics to add the state name to the list of cities.
The ABS has a downloadable ESRI Shapefile, which basically is a vector map of all the borders for states in Australia. This, with a little bit of data cleaning using Pandas DataPrep, and a quick dirty R script would allow me to add the state name to the CSV.
So, first we start with the raw CSV file that I was given:
| Suburb Name | lat | long | |
|---|---|---|---|
| 0 | Aberfoyle | 30° 21’30″S | 152° 2’30″E |
| 1 | Adaminaby | 35° 58’30″S | 148° 51’0″E |
| 2 | Adelaide | 34° 56’0″S | 138° 35’30″E |
| 3 | Adelong | 35° 18’35″S | 148° 1’0″E |
| 4 | Agnes Water | 24° 17’0″S | 151° 49’0″E |
| … | … | … | … |
| 3095 | Yumali | 35° 28’0″S | 139° 51’30″E |
| 3096 | Yuna | 28° 23’0″S | 114° 54’30″E |
| 3097 | Yuna East | 28° 25’30″S | 115° 10’0″E |
| 3098 | Yunta | 32° 35’0″S | 139° 28’0″E |
| 3099 | Zamia Creek | 24° 32’30″S | 149° 36’0″E |
import pandas
csv = pandas.read_csv("city_locations.csv")
import pandas as pd
import numpy as np
from dataprep.clean import clean_lat_long
df = pd.DataFrame(csv)
cleaned = clean_lat_long(df, lat_col="lat", long_col="long", split=True)
cleaned = cleaned[cleaned.lat_clean.lt(0)]
cleaned = cleaned[cleaned.long_clean.gt(0)]
cleaned.to_csv("clean.csv")
Running this script would give me an output file that contained the latitude and longitude converted from DMS (Degrees, Minutes and Seconds) to decimal values – skipping the rows that could not be processed correctly, ready for the next processing step.
| SZU | lat | long | lat_clean | long_clean | |
|---|---|---|---|---|---|
| 0 | Aberfoyle | 30° 21’30″S | 152° 2’30″E | -30.3583 | 152.0417 |
| 1 | Adaminaby | 35° 58’30″S | 148° 51’0″E | -35.9750 | 148.8500 |
| 2 | Adelaide | 34° 56’0″S | 138° 35’30″E | -34.9333 | 138.5917 |
| 3 | Adelong | 35° 18’35″S | 148° 1’0″E | -35.3097 | 148.0167 |
| 4 | Agnes Water | 24° 17’0″S | 151° 49’0″E | -24.2833 | 151.8167 |
| … | … | … | … | … | … |
| 3092 | Yumali | 35° 28’0″S | 139° 51’30″E | -35.4667 | 139.8583 |
| 3093 | Yuna | 28° 23’0″S | 114° 54’30″E | -28.3833 | 114.9083 |
| 3094 | Yuna East | 28° 25’30″S | 115° 10’0″E | -28.4250 | 115.1667 |
| 3095 | Yunta | 32° 35’0″S | 139° 28’0″E | -32.5833 | 139.4667 |
| 3096 | Zamia Creek | 24° 32’30″S | 149° 36’0″E | -24.5417 | 149.6000 |
Using Rlang, we import the Shapefile from the ABS, import the cleaned CSV file with decimal lat/long points, and use st_intersects from the sf package to determine what state a given city is in, based on it’s lat/long location.
library(sf)
library(dplyr)
library(sp)
library(progress)
map = read_sf("1270055004_sos_2016_aust_shape/SOS_2016_AUST.shp")
nc_geom <- st_geometry(map)
latLong <- read.csv(file = 'cleaned.csv')
crsFormat = st_crs(map)
pnts_sf <- st_as_sf(latLong, coords = c('long_clean', 'lat_clean'), crs = crsFormat)
pnts <- pnts_sf %>% mutate(
intersection = as.integer(st_intersects(geometry, map)),
area = if_else(is.na(intersection), '', map$STE_NAME16[intersection]),
size = if_else(is.na(intersection), '', map$SOS_NAME16[intersection]),
.keep = c("all")
)
write.csv(pnts, "with-intersections.csv")
This should leave you with a CSV file that contains the state name that the given points are in.
The best Apple dongle. Is it a Dell DA310?
/ | Leave a CommentMy attempts to get the perfect video out of an Apple MacBook to the Dell S2721QS finally is a success! It’s all thanks to Dell. I guess it makes sense. Dell makes the monitor, so I suppose having the Dell DA310 USB-C companion adapter is the right thing to do.
That said, I did expect the Apple adapter to “just work”. I ditched it for the more capable (and gigabit network-enabled!) Dell DA310. The Apple adapter displayed blurry text and icons that really were not sharp. It had to go!
The adapter will work with both Intel and Apple Silicon arm64/M1 MacBook’s. I have tested the adapter with macOS 10.14, 10.15, 11.6 and 12.2. See the bottom of the article to see some notes on how to get the Ethernet port working correctly.

First, to the Apple USB-C Digital AV Multiport Adapter. You need to be aware that there are two versions of these adapters. Model A1621, which supports a 4k output (3840 x 2160) at 30hertz (30 frames per second), and the Model A2119, which supports 4k video at 3840 x 2160 at 60hertz. Apple does have a support document, which explains the difference between the two adapters (pictured above, left). Needless to say, I would suggest a different adapter.
One thing to watch out for when purchasing a USB-C adapter is how they mention support for 4k resolutions. Even though an adapter might “support” 4k video, it does not mean that the adapter will deliver a perfect image. Apple mentions that their Model A1621 version of the AV Adapter does not allow screens to operate at a high refresh rate. Even the most recent current model, the A2119 does support high refresh rates – on paper – but not always with a high-quality image.
Why do I care about refresh rates?
High refresh rates allow for buttery smooth window movements. A low refresh rate will effect everything from the latency of key presses appearing on the screen, to the smoothness of the mouse cursor on the screen when physically moving the mouse. The limited 30 frames per second of the slower refresh rate afforded by Apple on their older AV Adapters (bottom left adapter, pictured above) is extremely noticeable.
Using a MacBook with a 30-hertz resolution makes the computer feel frustratingly slow.
Luckily, updating the AV Adapter to the Model A2119 (top left adapter, pictured above) does give 4k video at 60 fps. That said, the quality of the output on the A2119 at a high refresh rate is sad. The colours appear washed out. It almost seems as though the images data is heavily compressed. It’s either done by the MacBook or the USB-C adapter before the data is sent to the display.


It’s hard to be able to visualize the difference between them both side by side. You will notice that lines, such as the diagonal lines on the IntelliJ IDEA icon appear jagged. Switching between the two though, the difference is immeasurable.

I’m not sure what exactly is causing this issue. Looking inside System Information, the resolution, refresh rate, connection type settings, and frame buffer depth were all the same.
Read more »Extracting Dell colour profiles on macOS without Windows
/ | Leave a CommentDell is notorious for not really supporting Apple’s operating system very well. It’s not just their monitors, but other accessories like their USB-C docks.
It’s a shame. I think that Dell has pretty high quality gear.
I recently acquired a Dell S2721QS, and wanted to extract the files that are provided in their Windows driver to determine what exactly what was in there. After a quick look, it turns out, not that much. That being said, the ICC/ICM file provided with the driver pack may be useful for use on macOS.
Either way, I recently wanted to install the colour profiles that come with Dell monitors (or can be downloaded from the Dell website) on my Mac, but could not find an easy way to extract the ICC/ICM files and install them.
Starting with the downloaded file, DELL_S2721QS-MONITOR_A00-00_DRVR_KTRRG.exe I extracted the file using Binwalk.
# binwalk -D '.*' --extract ./DELL_S2721QS-MONITOR_A00-00_DRVR_KTRRG.exe DECIMAL HEXADECIMAL DESCRIPTION -------------------------------------------------------------------------------- 0 0x0 Microsoft executable, portable (PE) 90592 0x161E0 7-zip archive data, version 0.4
Here I had two extracted files. The 7-zip archive is the one we were looking for.
# cd _DELL_S2721QS-MONITOR_A00-00_DRVR_KTRRG.exe.extracted # ls total 616 drwxr-xr-x 4 tim staff 128 Jul 19 17:06 . drwxr-xr-x 4 tim staff 128 Jul 19 17:06 .. -rw-r--r-- 1 tim staff 358345 Jul 19 17:06 0 -rw-r--r-- 1 tim staff 267753 Jul 19 17:06 161E0 # file 161E0 161E0: 7-zip archive data, version 0.4 # 7z x 161E0 Everything is Ok Files: 5 Size: 756506 Compressed: 267753
Now that the extraction is complete, there should be 7 files in the directory.
# ls total 1360 drwxr-xr-x 9 tim staff 288 Jul 19 17:09 . drwxr-xr-x 4 tim staff 128 Jul 19 17:06 .. -rw-r--r-- 1 tim staff 358345 Jul 19 17:06 0 -rw-r--r-- 1 tim staff 267753 Jul 19 17:06 161E0 -rw-r--r-- 1 tim staff 540216 Jul 22 2019 'Dell Monitor Driver Installer.exe' -rw-r--r-- 1 tim staff 2600 May 27 2020 S2721QS.icm -rw-r--r-- 1 tim staff 3071 May 27 2020 S2721QS.inf -rw-r--r-- 1 tim staff 200360 Mar 28 2012 _x64help.exe -rw-r--r-- 1 tim staff 10259 May 27 2020 s2721qs.cat
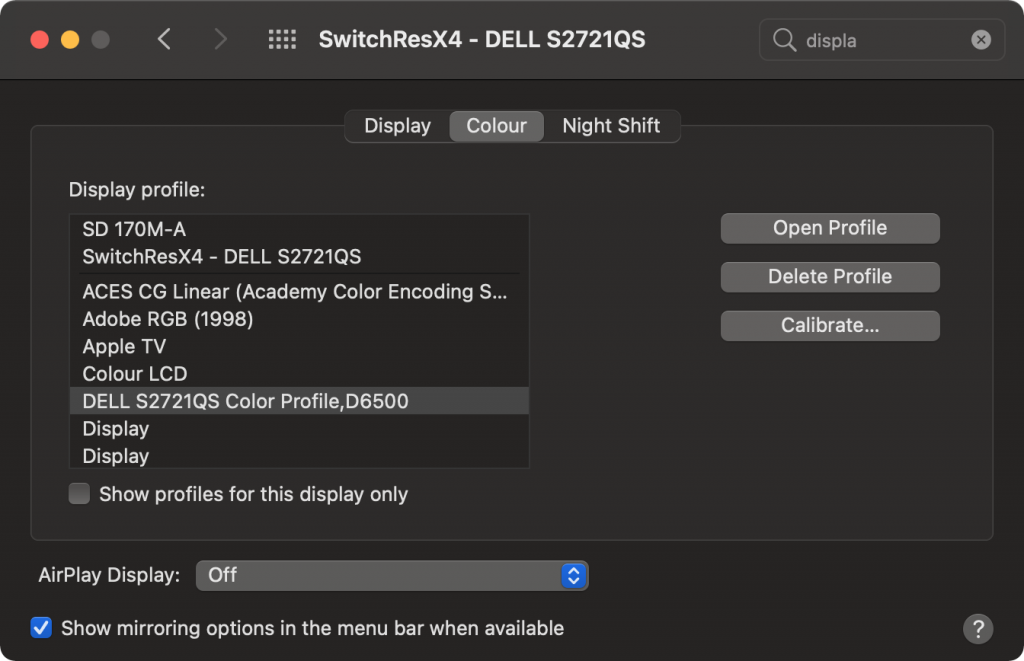
Indeed, there is. That S2721QS.icm file looks like it’s exactly what we are looking for! Simply copy it into ColorSync
# file S2721QS.icm S2721QS.icm: Microsoft color profile 2.0, type KCMS, RGB/XYZ-mntr device by KODA, 2600 bytes, 30-4-2020 12:15:03, PCS Z=0xd32b "DELL S2721QS Color Profile,D6500" # sudo cp S2721QS.icm /Library/ColorSync/Profiles/Displays
After that, you should be able to glaze into your Dell monitor with all the correct colour curves.
Creating a new WordPress admin account with only database access
/ | Leave a CommentCreating a new WordPress user when you don’t have access to WordPress but do have access to the hosting control panel is rather simple.
Simply replace the strings in the first INSERT query that are wrapped around square brackets, and run the SQL statement on your server. You will then be able to successfully log into WordPress.
INSERT INTO `wp_users` (
`user_login`, `user_pass`, `user_nicename`, `user_email`,
`user_url`, `user_registered`, `user_activation_key`,
`user_status`, `display_name`
) VALUES (
'[username]', MD5('[password]'), '[username]', '[email-address]',
'', NOW(), '', 0, '[username]'
);
--
-- Make MySQL remember the ID for the user just inserted for use later
--
SET @MY_USER_ID = LAST_INSERT_ID();
--
-- Add the magic sauce to have WordPress know the user is an admin...
--
INSERT INTO `wp_usermeta` (`user_id`, `meta_key`, `meta_value`) VALUES
(
@MY_USER_ID, 'wp_capabilities',
'a:2:{s:13:"administrator";s:1:"1";s:14:"backwpup_admin";b:1;}'
),
(@MY_USER_ID, 'wp_user_level', '10'),
(@MY_USER_ID, 'wp_dashboard_quick_press_last_post_id', '620'),
(@MY_USER_ID, 'wp_user-settings', 'editor=tinymce&uploader=1&hidetb=1'),
(@MY_USER_ID, 'wp_user-settings-time', UNIX_TIMESTAMP());
Checking what processes need to be restarted after a system upgrade
/ | 2 Comments on Checking what processes need to be restarted after a system upgradeWith updates going on in the last couple of months for various packages, such as OpenSSL and GLibC which have fixed a number of important security vulnerabilities, I thought I might share a one liner that might save you one day.
sudo lsof -n | grep -v \#prelink\# | grep -e '\.so' | grep -e DEL | grep -e lib | grep -v ^init | sed -re 's|^([^0-9]*)\s*([0-9]*)[^/]*(\/.*)$|\1 (\2) \3|' | sort -u
Running lsof will list all of the currently opened files from processes running on your system. -n will stop lsof from resolving hostnames for processes that have opened network ports to different processes (such as your webserver, mail server etc)
Running grep a couple of times will ensure that we find all the processes that have loaded a shared binary that has been deleted.
Note that the “init” process has been excluded. This is done on purpose. init can not be restarted without rebooting or otherwise killing the system.
The sed magic will show a list of all the processes and their PID’s, along with the library that was deleted that triggered it being listed as an application that should be restarted.
tim@srv215.production [~]# REGEX='^([^0-9]*)\s*([0-9]*)[^/]*(\/.*)$|\1 (\2) \3'
tim@srv215.production [~]# sudo lsof -n | grep -v \#prelink\# \
| grep -e '\.so' | grep -e DEL | grep -e lib \
| grep -v ^init \
| sed -re "s|$REXEG|" | sort -u
auditd (1802) /lib64/ld-2.12.so
auditd (1802) /lib64/libc-2.12.so
auditd (1802) /lib64/libm-2.12.so
auditd (1802) /lib64/libnsl-2.12.so
auditd (1802) /lib64/libnss_files-2.12.so
auditd (1802) /lib64/libpthread-2.12.so
auditd (1802) /lib64/librt-2.12.so
Note that this will not work if the application is dynamically loaded (for example using dlopen(3)) or if the application is statically linked.
Taylor Otwell on Laravel
/ | Leave a CommentI promised myself never to release Laravel until I had great documentation, and I never release a new version until the documentation is totally up to date. Any PHP programmer can pick up Laravel and start using it in a matter of minutes. The expressiveness of the code itself and the great documentation truly make coding enjoyable.
Google+: Please give us a write API
/ | Leave a CommentIt seems that Google has been on a relentless campaign to get Google+ to work. From only allowing YouTube users to comment with a Google+ account to their desperate attempts to integrate it into Google’s own search results (which seem to be all but gone now…) it all seems to be very pointless on Google’s behalf.
Their problems have been two sided. Firstly, they have battled the massive loss of data that has happened thanks to Facebook now having much of the information that was once the forte of GMail (although they still do have YouTube) but on their own side, it seems that Google have still not really wanted to side with people trying to integrate with their own social platform.
With Facebook and Twitter, it is extremely simple to get external applications to post to the respective accounts. Seriously, you can get an API account set up literally in three minutes, and information posted on either of the respective streams within another 20 minutes.
Google+? Dream on.
Despite the fact that Google has released this functionality to a select group of partners (of which only HootSuite comes to mind…), Google after more then three years seems to feel that this functionality should be all but unavailable.
Issue #43 has been around in Google+’s platform issue tracker since September 2011 and to this day there have been nothing but excuses.
More then 400 developers ask Google for a feature inside their API, and the best that Google can come up with is that their API needs to be perfect before they release it.
People have their hopes on write access to Google+ being a well kept secret that is to be revealed at Google I/O this year, but I am unsure about that.
I don’t get what is the deal? Why does Google have a social platform that still has no documentation for writing to the Google+ streams? You look at all of the major social platforms like Twitter and Facebook and there is much growth that can be attributed to having an API.
Google’s mission is “[…] to organize the world’s information and make it universally accessible and useful”. Here are developers that are hanging to give you (Google) information. Google: please get this; we want to be able to feed you data, and your not allowing is to put it into your hands.
With Facebook dropping it’s organic reach, it’s no longer useful to disseminate information on that platform, as the cost to benefit ratio is deteriorating as Facebook tries to get us to pay more to get the organic reach of days gone past.
Google’s inability to listen to clients wants (and somewhat arguably, their needs) have been their downfall.
They had their chance with a nice simple interface and the ability to comfortably share long form texts to be the replacement for blogs. Now all Google+ feels like a really noisy version of medium.com.
These days, all I use Google+ for is to complain about the fact that I can’t post to Google+ using software, and instead must use their web interface. As someone who wants to post Google+ content for five different content brands with one or two pieces of original content per brand with twelve different writers, this is almost impossible. I don’t want to hand out these login details to my writers, they should be able to share the content from within their content management platform.
But really, this ranting is all in vain. I already quit Google+ for my brands last month. I asked Google for these features, they never came.
No difference was ever felt. Even with Facebook’s decreased organic reach, one brand that has more followers on Facebook receives a higher click through rate for content then a Google+ page with more followers.
Using files or Semaphores for long running process locks with PHP
/ | 2 Comments on Using files or Semaphores for long running process locks with PHPLast week I spoke at SydPHP, which was hilariously horrible due to my lack of public speaking skills.
During my Introduction to Laravel & Composer there was a very interesting question posted asking about an issue that he came across while developing a cron that was running on his server.
The process was set to be started every minute to go and process some data. The problem was he didn’t know how long it would take for the data to processed. Sometimes it could take five seconds, other times it could take five days.
To try and solve the problem, the process would attempt to block the PHP process by running by using the sem_acquire function. This worked. That is, until the same process was launched multiple times and the request to acquire a semaphore would ultimately fail.
So, the first part of the problem is that semaphores like everything else to do with a computer have a limit to them. Semaphores are different to other methods of locking because they main purpose for existing is to control access to data when developing software that will be needing to access data from multiple threads (i.e., parallel programming).
Viewing semaphore limits can be done by the ipcs command, which is provided by the util-linux-ng package in RHEL and Arch Linux.
root@staging [~]# ipcs -ls
------ Semaphore Limits --------
max number of arrays = 128
max semaphores per array = 250
max semaphores system wide = 32000
max ops per semop call = 32
semaphore max value = 32767
A call to sem_get will add one extra array into the kernel if the key has not already been used, which is fine, but the important part is that at least on RHEL, there is a limit of 250 semaphores per array. This means that after the 251th attempt, sem_acquire will fail to get a semaphore.
There is no simple way to fix this. There is essentially two options. Either the maximum number of semaphores created is increased, or you create less semaphores. You don’t really want to add more semaphores though, and the number of arrays set by default is actually a very forgiving number.
If you wanted to see what the kernel’s current settings for semaphores are without using ipcs, you could use find the information from /proc/sys/kernel/sem.
root@timgws ~ # cat /proc/sys/kernel/sem
250 32000 32 128
The numbers are separated by tabs, and are represented in this order:
250The number of semaphores per array.32000The limit of semaphores system wide (should be roughly 250*128 i.e., [semaphores per array]x[max number arrays]).32Ops per semop call128Number of arrays
The configuration can be written out by using printf
printf '250\t32000\t32\t200' >/proc/sys/kernel/sem
… but you said semaphores are bad…
Well, not exactly. Semaphores are amazing for the purpose they were built for, that is, preventing processes from accessing a resources while another process is performing operations on it. However, if you are not going to need access to the resources straight away, then you don’t want to use a semaphores, and the reasons are plentiful.
Files are awesome when it comes to locking two processes from running at the same time. It’s not just me who thinks that, too!
RPM uses files to lock the application. When you attempt to install two packages from two processes at one time, the process that is launched the second time will fail, thanks to the first application creating a file saying that RPM is locked.
flock is more portable than sem_get. (Semaphores don’t work on Windows, files however do work on Windows. With caveats.).
Here is a simple lock class that I wrote. It will check if a file exists, if it doesn’t, it will be created.
<?php
class ProcessLock {
private $lockFilePath = '/tmp/tim.lock';
function aquire() {
if (file_exists($this->lockFilePath))
return false;
// Get the PID and place into the file...
$pid = getmypid();
// Hopefully our write is atomic.
@file_put_contents($this->lockFilePath, $pid);
if (!file_exists($this->lockFilePath))
return false; // our file magically disapeared?
$contents = file_get_contents($this->lockFilePath);
$lockedPID = (int)$contents
if ($pid === $lockedPID)
throw new Exception("Another process locked before us for somehow");
return false;
}
function release() {
@unlink($this->lockFilePath);
return true;
}
}
To use this class, we simply create a new instance, and attempt to acquire the lock. If successful, then we run our code.
$myLock = new ProcessLock();
$gotLock = $myLock->aquire();
if ($gotLock) {
// ... this is where I put all of my code that only
// one process should run at a time
// Then we release
$myLock->release();
} else {
echo "Can't run, sorry";
exit(2);
}
When the lock has been acquired, you might get bonus points if you check if the process is still running or if the lock is actually stale. This can be done by checking if /proc/$lockedPID exists, and if it does, if /proc/$lockedPID/exe is still symlinked (using readlink) to PHP_BINARY (though this will only work on Linux).
Nagios plugin for checking the status of supervisord processes
/ | Leave a CommentIf you have never used it before, supervisor is an application that runs on your server to monitor a number of different applications. With supervisord, you get all of the benefits of turning long-running applications into daemons without all the extra code required to make that happen natively.
The configuration for supervisord is extremely flexible, and one of the things that it will allow you to do is go and configure how many times a process will get restarted, the minimum amount of time an application should be running and what the action should be if your long-running process crashes (i.e., should it restart, or do nothing?).
An example configuration for a project that is monitored by supervisors:
[program:www-api]
command=/opt/nodejs/bin/node /opt/<project>/server.js
user=backend
numprocs=10
directory=/opt/<project>
autostart=true
startsecs=10
process_name=server_%(process_num)s
redirect_stderr=true
stdout_logfile=/home/backend/app/storage/logs/daemon.log
Inside the configuration files of Supervisor, you specify the process that you want to monitor, how many copies of the same program that you want to run, and then reload supervisor. If that program crashes, supervisor will detect the signal from the child process it spawned and will go and restart the process for you. No more wondering if your process is still running, and no more running your applications in screen.
Also, there is no more second guessing if your application is still running. Almost, that is.
The program will follow all the rules that you specify for restarting processes.
Luckily, Supervisor comes backed in with a web server, which is configured by setting up the [inet_http_server] section inside /etc/supervisord.conf. By giving Supervisor an IP address and port to listen to, you will get an integrated interface where all of the processes that are currently running are listed.
Which is fine for development, but when your running long-running apps in production, normally you would also want to have those processes monitored to ensure that there are no issues with the availability of your application.
Queue the nagios-supervisord-processes repository.
check_supervisor is a plugin for use with Nagios that uses supervisor’s XML-RPC API that is built into the same web server that is provided by Supervisord to check the status of any processes that are set up to be running inside supervisord.
If you have nagios checks already being performed, configuration is mind-numbingly simple to get up and running.
Install the script into your user scripts directory inside Nagios, add a command template and finally add one service for each program or service you want to monitor.
The nagios check will automatically find out if any of the processes started are not running and alert your system administrators accordingly.
Check out the project over at GitHub and open up an issue if you come across any issues or see any bugs.